注:最后两位为锁标记位,倒数第三位是偏向标记,如果是1表示是偏向锁;合并单元格的位数就是 该字段的位数,例如hash code共25(23+2)位。
另外,对于偏向锁,如果Thread ID = 0,表示未加锁
Synchronized锁升级:偏向锁 → 轻量级锁 → 重量级锁
Synchronized 会从无锁升级为偏向锁,再升级为轻量级锁,最后升级为重量级锁,这里的轻量级锁就是一种自旋锁
锁只能按照上述的顺序进行升级操作,锁只要升级之后,就不能降级
偏向锁
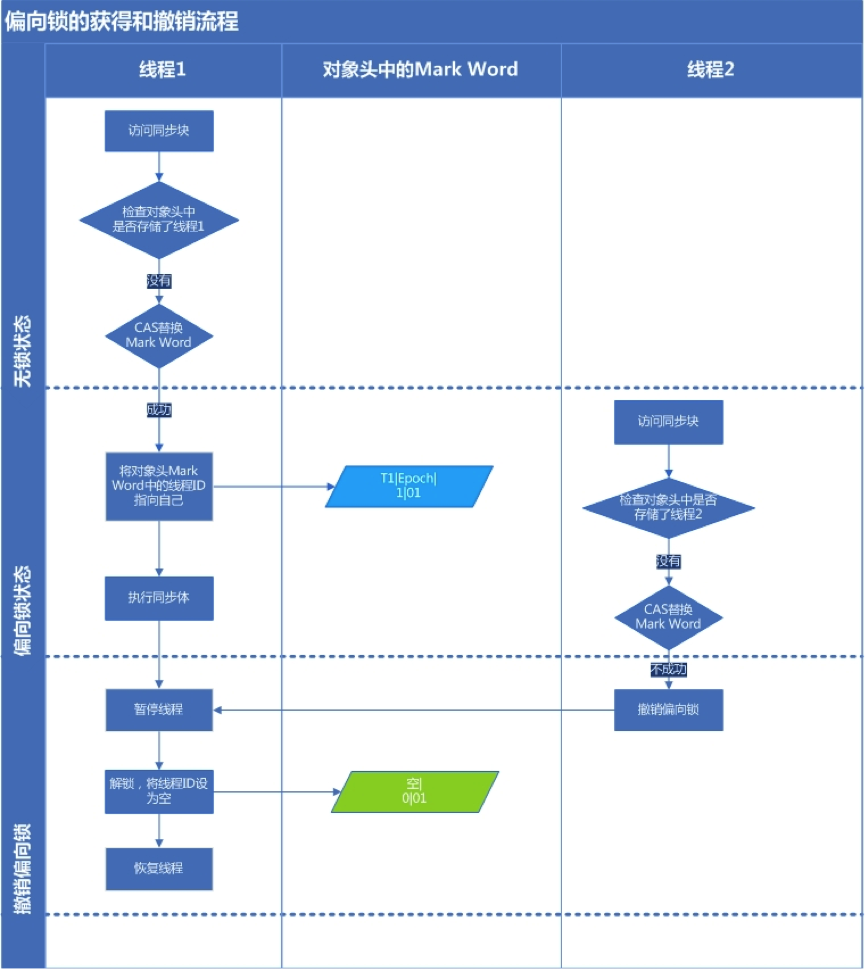
初次执行到 Synchronized 代码块的时候,锁对象变成偏向锁(通过CAS修改对象头里的锁标志位),字面意思是 ”偏向于第一个获得它的线程“ 的锁
偏向锁是 JDK 默认启动的选项,可以通过 -XX:-UseBiasedLocking 来关闭偏向锁。另外偏向锁默认不是立即就启动的,在程序启动后,通常有几秒的延迟,可以通过命令 -XX:BiasedLockingStartupDelay=0 来关闭延迟
执行完同步代码块后,线程并不会主动释放偏向锁。当第二次到达同步代码块时,线程会判断此时持有锁的线程是否就是自己(持有锁的线程ID也在对象头里),如果是则正常往下执行。由于之前没有释放锁,这里也就不需要重新加锁。如果自始至终使用锁的线程只有一个,很明显偏向锁几乎没有额外开销,性能极高
引入偏向锁的目的是为了没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。偏向锁在无竞争的情况下会把整个同步都消除掉
偏向锁的加锁
如果 JVM 支持偏向锁,那么在分配对象时,分配一个可偏向而未偏向的对象(Mark Word的最后3位 为101,并且Thread ID字段的值为0)
然后,当一个线程访问同步块并获取锁时,将通过 CAS(Compare And Swap) 来尝试将对象头中的 Thread ID字段设置为自己的线程号,如果设置成功,则获得锁,那么以后线程再次进入和退出 同步块时,就不需要使用 CAS 来获取锁,只是简单的测试一个对象头中的Mark Word字段中是否存储着指向当前线程的偏向锁
如果使用 CAS 设置失败时,说明存在锁的竞争,那么将执行偏向锁的撤销操作 (revoke bias),将偏向锁升级为轻量级锁
偏向锁升级轻量级锁
当线程1访问代码块并获取锁对象时,会在 Java对象头和栈帧中记录偏向的锁的 Thread ID,因为偏向锁不会主动释放锁,因此以后线程1再次获取锁的时候,需要比较当前线程的 Thread ID 和Java对象头中的 Thread ID是否一致,如果一致(还是线程1获取锁对象),则无需使用 CAS 来加锁、解锁;如果不一致(其他线程,如线程2要竞争锁对象,而偏向锁不会主动释放因此还是存储的线程1的 Thread ID)
那么需要查看 Java对象头中记录的线程1是否存活:
- 如果没有存活,那么锁对象被重置为无锁状态,其它线程(线程2)可以竞争将其设置为偏向锁
- 如果存活,那么立刻查找该线程(线程1)的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程1,撤销偏向锁,升级为轻量级锁,如果线程1 不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程
简单来说:线程A第一次执行完同步代码块后,当线程B尝试获取锁的时候,发现是偏向锁,会判断线程A是否仍然存活
- 如果线程A仍然存活,将线程A暂停,此时偏向锁升级为轻量级锁,之后线程A继续执行,线程B自旋(自旋超过一定的次数后,会膨胀成重量级锁)
- 但是如果判断结果是线程A不存在了,则线程B持有此偏向锁,锁不升级
1 | static BiasedLocking::Condition revoke_bias(oop obj, bool allow_rebias, |
1 | //针对上面的伪代码实现 |
小结:
撤销偏向的操作需要在全局检查点执行。我们假设线程A曾经拥有锁(不确定是否释放锁), 线程B来竞争锁对象,如果当线程A不在拥有锁时或者死亡时,线程B直接去尝试获得锁(根据是否允许重偏向(rebiasing),获得偏向锁或者轻量级锁);如果线程A仍然拥有锁,那么锁升级为轻量级锁,线程B自旋请求获得锁
轻量级锁
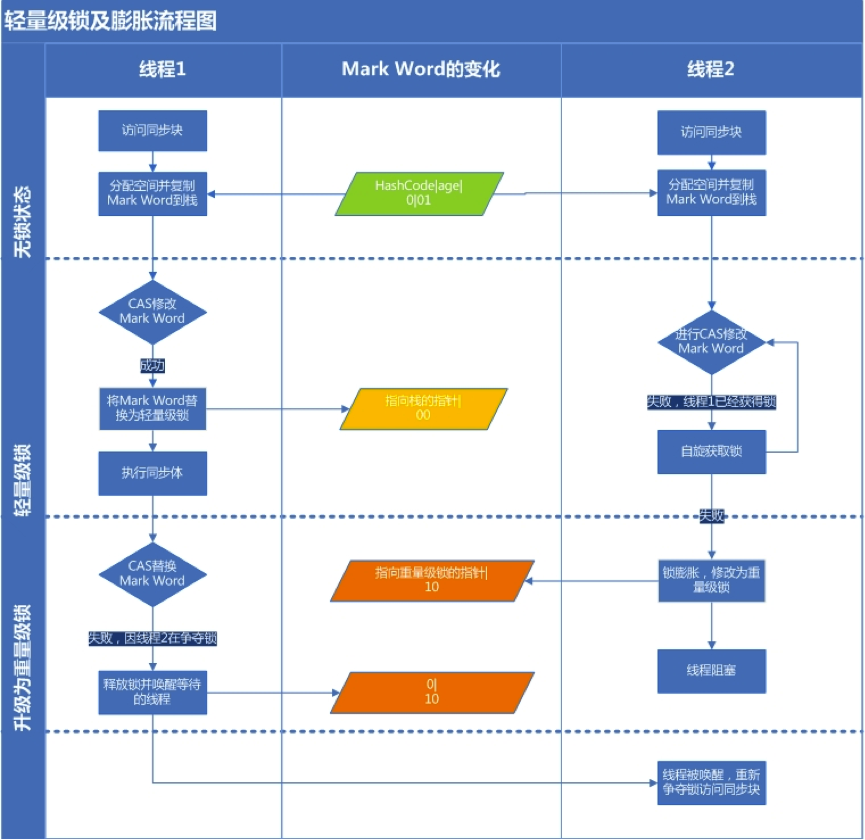
轻量级锁不是使用操作系统互斥量来实现锁, 而是通过 CAS 操作来实现锁。当线程获得轻量级锁后,可以再次进入锁,即锁是可重入(Reentrance Lock)的
在轻量级锁的加锁阶段,如果线程发现对象头中Mark Word已经存在指向自己栈帧的指针,即线程已经获得轻量级锁,那么只需要将0存储在自己的栈帧中(此过程称为递归加锁);在解锁的时候,如果发现锁记录的内容为0, 那么只需要移除栈帧中的锁记录即可,而不需要更新Mark Word
在轻量级锁状态下继续锁竞争,没有抢到锁的线程将自旋(即不停地循环判断锁是否能够被成功获取)
忙等
长时间的自旋操作是非常消耗资源的,一个线程持有锁,其他线程就只能在原地空耗CPU,执行不了任何有效的任务,这种现象叫做忙等(busy-waiting)
如果多个线程用一个锁,但是没有发生锁竞争,或者发生了很轻微的锁竞争,那么 Synchronized 就用轻量级锁,允许短时间的忙等现象。短时间的忙等,换取线程在用户态和内核态之间切换的开销
轻量级锁加锁
- 线程在执行同步块之前,
JVM会先在当前的线程的栈帧中创建所记录的空间,用于存储对象头中的 Mark Word的拷贝 - 然后线程尝试使用
CAS将对象头中的Mark Word替换为指向锁记录(Lock Record)的指针 - 如果成功,当前线程获得轻量级锁
- 如果失败,虚拟机先检查当前对象头的Mark Word 是否指向当前线程的栈帧
- 如果指向,则说明当前线程已经拥有这个对象的锁,则可以直接进入同步块执行操作
- 否则表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。当竞争线程的自旋次数达到界限值(
threshold),轻量级锁将会膨胀为重量级锁
重量级锁
(有个计数器记录自旋次数,默认允许循环10次,可以通过虚拟机参数更改)
如果锁竞争情况严重,某个达到最大自旋次数的线程,会将轻量级锁升级为重量级锁(依然是 CAS 修改锁标志位,但不修改持有锁的线程ID)
当后续线程尝试获取锁时,发现被占用的锁是重量级锁,直接进入堵塞状态,此时不消耗CPU,然后等拥有锁的线程释放锁后,唤醒堵塞的线程, 然后线程再次竞争锁
在
JDK1.6之前,Synchronized直接加重量级锁,很明显现在得到了很好的优化
锁竞争
如果多个线程轮流获取一个锁,但是每次获取锁的时候都很顺利,没有发生阻塞,那么就不存在锁竞争。只有当某线程尝试获取锁的时候,发现该锁已经被占用,只能等待其释放,这才发生了锁竞争
锁消除
锁消除指的是虚拟机即使编译器在运行时,如果检测到那些共享数据不可能存在竞争,那么就执行锁消除。锁消除可以节省毫无意义的请求锁的时间
锁粗化
如果一系列的连续操作都对同一个对象反复加锁和解锁,频繁的加锁操作就会导致性能损耗
如果虚拟机探测到由这样的一串零碎的操作都对同一个对象加锁,将会把加锁的范围扩展(粗化)到整个操作序列的外部
比如说有多个append方法,对每一个方法都加锁,此时会进行锁粗化,将第一个append直到最后一个append包起来,这样就只会进行一次的加锁操作而不是多次
小结
一个锁只能按照 偏向锁、轻量级锁、重量级锁 的顺序逐渐升级(也叫锁膨胀),不允许降级
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,与执行非同步方法仅存在纳秒级的差距 | 如果线程间存在竞争,会带来额外的锁撤销的消耗 | 适用于只有一个线程访问同步块的情况 |
| 轻量级锁 | 竞争的线程不会堵塞,提高了程序的响应速度 | 始终得不到锁的线程,使用自旋会消耗CPU | 追求响应时间,同步块执行速度非常块,只有两个线程竞争锁 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU | 线程堵塞,响应时间缓慢 | 追求吞吐量,同步块执行速度比较慢,竞争锁的线程大于2个 |
中断锁
Java并没有提供任何直接中断某线程的方法,只提供了中断机制
何谓“中断机制”?
线程A向线程B发出 “请你停止运行” 的请求(线程B也可以自己给自己发送此请求),但线程B并不会立刻停止运行,而是自行选择合适的时机以自己的方式响应中断,也可以直接忽略此中断
也就是说,Java的中断不能直接终止线程,而是需要被中断的线程自己决定怎么处理
如果线程A持有锁,线程B等待获取该锁。由于线程A持有锁的时间过长,线程B不想继续等待了,我们可以让线程B中断自己或者在别的线程里中断它,这种就是可中断锁。在Java中,synchronized就是不可中断锁,而Lock的实现类都是可中断锁